#Load maps and googlesheets4 and janitor as those are the packages we'll use.
library(maps)
library(googlesheets4)
library(janitor)
Attaching package: 'janitor'The following objects are masked from 'package:stats':
chisq.test, fisher.testHere are four problems for you to try. Don’t overly complicate your functions.
#Load maps and googlesheets4 and janitor as those are the packages we'll use.
library(maps)
library(googlesheets4)
library(janitor)
Attaching package: 'janitor'The following objects are masked from 'package:stats':
chisq.test, fisher.testR is a vectorized language, and one thing that means is that you can easily add values from vectors element-wise.
Make two vectors, each with 5 integers and save them as vector_1 and vector_2. Then make a function that will, add or subtract these vectors based on an argument called operation. Note that the answer also have five integers.
vector_1 <- c(1,2,3,4,5)
vector_2 <- c(2,2,2,2,2)
calculator <- function(vec1, vec2, operation ="add") {
if (operation == "add"){
vec1 + vec2
}
else{
vec1 - vec2
}
}
calculator(vector_1,vector_2)[1] 3 4 5 6 7The function below is broken. It’s syntax (the way it is typed) is not great. Your task is to fix it and make the style conform to the style guide. You’ll add paraenthesis and curley brackets, adjust spacing and consider why the else_if is black. Then when you run the function with default arguments and it’ll be fixed.
fix_me <- function(argument1 = "fixed", argument2= "broken") {
if (identical(argument1, argument2)){
print(argument2)
}
else if (argument1 == argument2){
print("still broken")
}
else{
print(argument1)
}
}
fix_me()[1] "fixed"Make a function that draws a map of every country where students in this class are from. Call it home_countries and have it take one argument, a vector of the names of countries students are from. You can access this vector with class_info$country after running the chunk below.
class_info <- read_sheet("https://docs.google.com/spreadsheets/d/1k9qA7XldtHB8-FZjmEymoUoeZJArS4tGy5gyVsvyLB0/edit?usp=sharing") |>
janitor::clean_names()
write.csv(class_info, "class_info.csv")class_info <- read.csv("class_info.csv")home_countries <- function(country_vector = c()) {
map(regions = country_vector)
}
home_countries(class_info$country)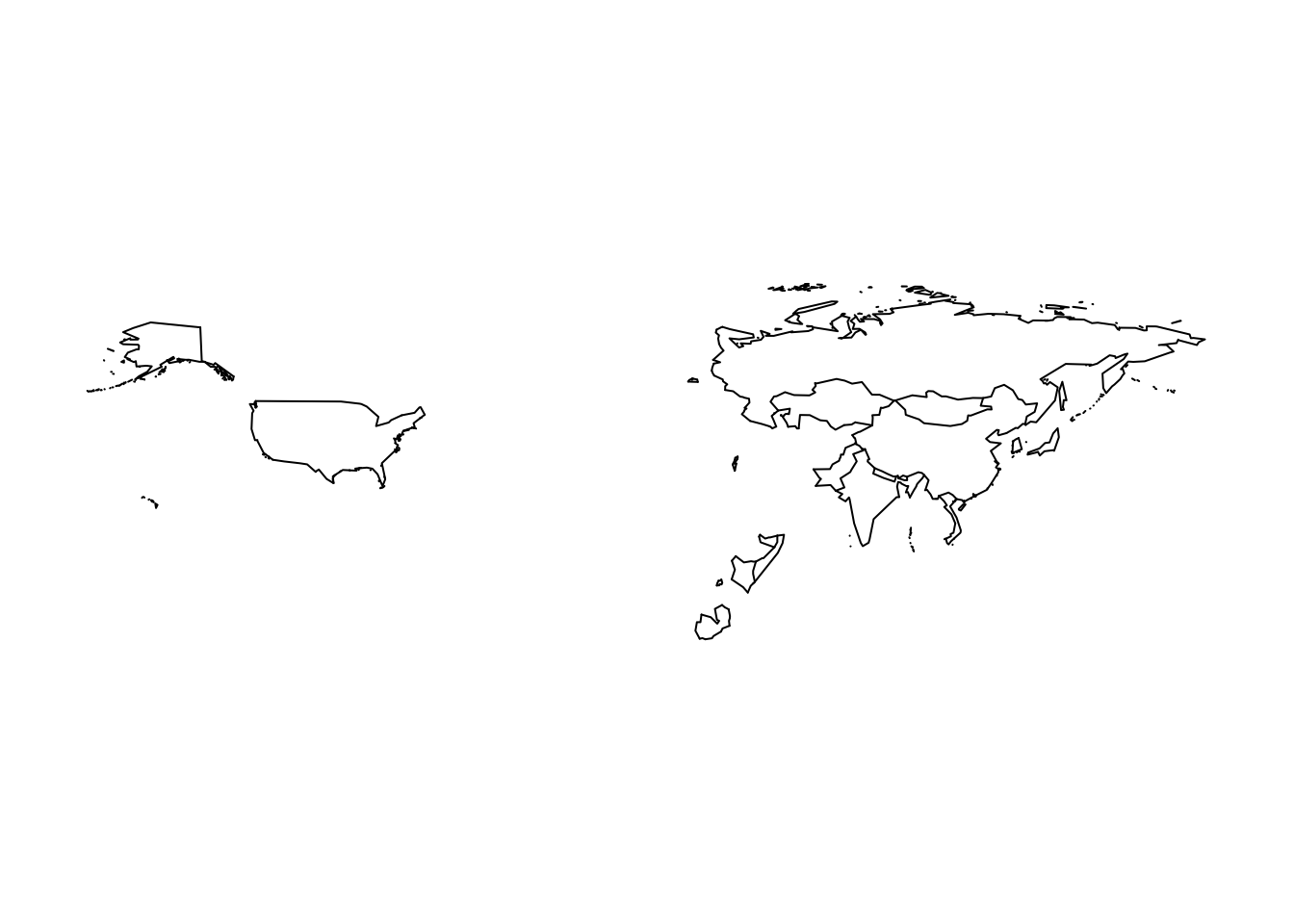
Make a function that draws a map of one student’s home country and colors it according to their computer OS (Mac or Windows). You should add a title stating the student’s name and their country. Your function should take one argument: the name of the student.
We will learn nicer tools for this, but for now use the subset() function to select a row of information for a student. Adding a [] bracket after the subset function will allow you to choose individual items from the data frame. (See examples below).
# If you want the row based on a student use subset. This gives my row
subset(class_info, preferred_name == "Nic" ) X timestamp preferred_name pronouns computer height siblings
8 8 2025-01-27 09:37:18.685 Nic He /Him Linux 69.5 4
other_course country class_year major required_for_major
8 I have never taken SDS 291 USA 2027 Data Science No
previos_r_experiance joke one_or_two_word_january_highlight
8 More than none <NA> Snow pretty#If you want a particular column you can access it with bracket notation. This chooses my pronouns.
subset(class_info, preferred_name == "Nic" )[9] country
8 USAhome_countries <- function(students_name) {
# A function that dras a picture of a student's country based and colors it based on their computer type.
student_region <- subset(class_info, preferred_name == students_name )[9] # Set the variable
student_computer <- subset(class_info, preferred_name == students_name )[4] # Set the region
if(student_computer == "Mac"){
color="purple"
}
else if(student_computer == "Windows"){
color = "blue"
}
else{
color = "red"
}
map(regions = student_region, fill = TRUE, col = color)
title(paste(students_name,"'s country:", student_region))
}
home_countries(students_name = "Nic")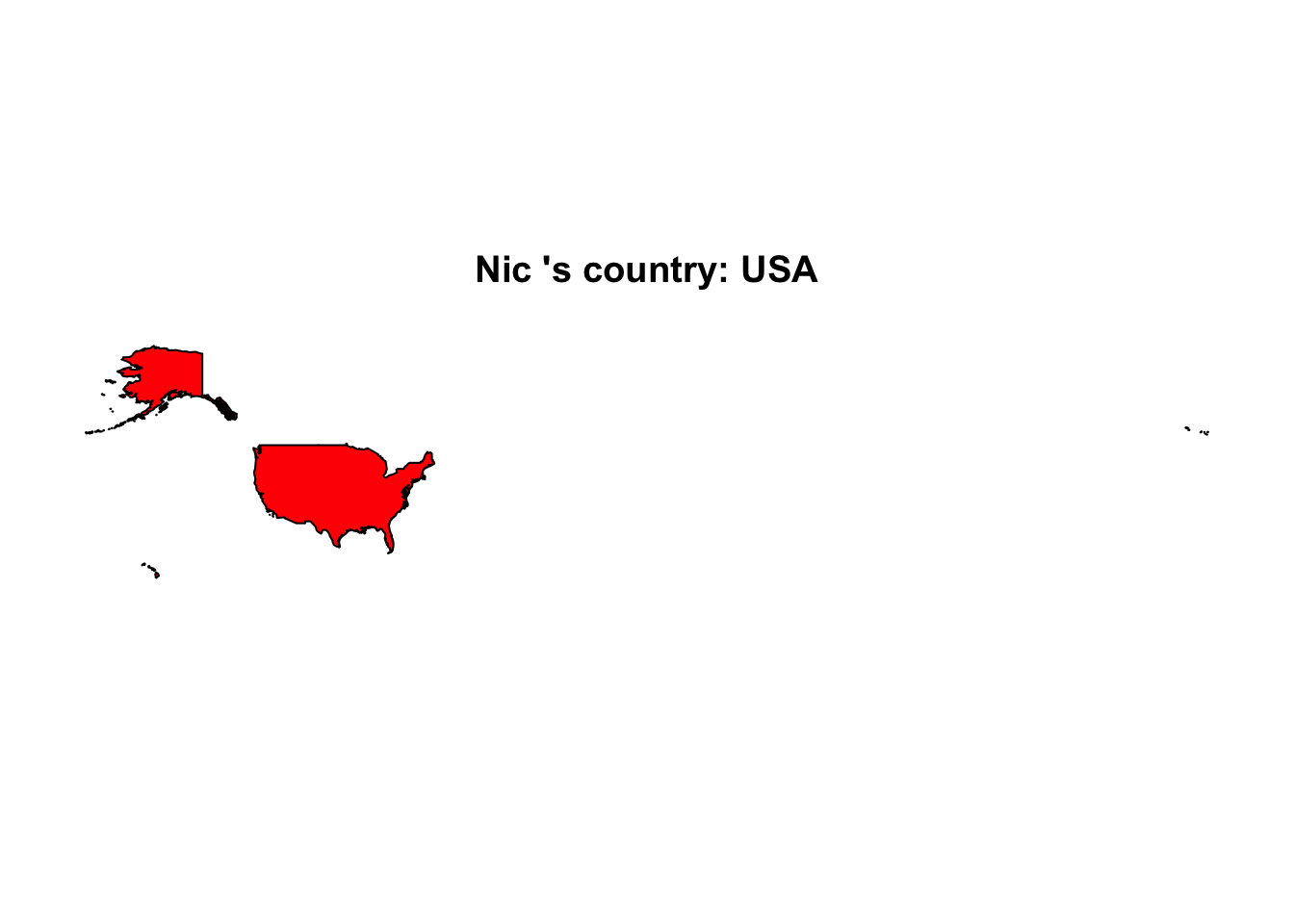
Keeping track of parenthesis while making functions is difficult some times. R has an option where you can make parenthesis rainbow colored. To turn it on go Tools > Global Options > Code > Display and select the checkbox near the bottom.
If you already have a some programming experience or you just finished the four problems above, take a look at the anonymous_function.qmd. In it you will see examples of other ways in which you can write functions in R. (Think lambda functions) We wont have too much time to get into these this semester, but they can simplify your programming.
After looking over anonymous functions. Try the following: Without using the mean() function, make an anonymous function the calculates the mean of a vector. You may want to consider sum() and length(). Be sure to remove the NAs with the subset() function. Then give you function a name, and use it to find the mean height of students. (We often use anonymous functions with other functions like purrr::map() but we wont get into that yet).
# The follow code removes all rows with missing heights
student_heights <- subset(class_info, !is.na(height))$height
# The mean is calculated as the sum of the values divided by the length of the values
mean_func <- function(vec) sum(vec)/length(vec)
#Using the heights
mean_func(student_heights)[1] 66.43281There is no built in mode function for R. The mode is the most common value from a vector. If your vector was c(2,1,1,1) then 1 would be the mode. Make a mode function and use it to find the most common number of siblings a student has. You may want to consider the discussion here. You can also do this with the count() function from the dplyr, like this dplyr::count() here.
# To calculate the mode from a vector.
mode_vector <- function(vec) {
# This breaks the vector into counts and stores it as a table.
count_of_vec <- table(vec)
# I am more comfortable with data frames than tables, so I changed count_of_vec to a df.
count_of_vec <- as.data.frame(count_of_vec)
#To subset I need the maximum from the frequencies
max_freq <- max(count_of_vec$Freq)
# Prints the answer
print("The mode is,")
subset(count_of_vec, Freq == max_freq)[1,1]
}
student_siblings <- class_info$siblings
mode_vector(student_siblings)[1] "The mode is,"[1] 1
Levels: 0 1 2 3 4 5 6 7 8 9